

How To Move Data from Repeating Fields in FileMaker
Repeating fields have a long and somewhat controversial history in FileMaker. If you want to start a heated discussion with another FileMaker developer, start one about repeating fields! Some developers love them, some hate them and then there are some like me, who appreciate them as another tool in the belt to be used to accomplish functions that would be hard to do without them.
If you started building FileMaker applications from scratch in more recent versions of the product you may not be very familiar with repeating fields and probably have never used them. You may even have an understanding of what they are but have never found a need to use them. If you’ve been using FileMaker for a long time or have taken over a legacy solution, chances are you’ve had to deal with them.
WHAT’S A REPEATING FIELD?
According to FileMaker’s glossary, a repeating field is a field that contains multiple, separate values. Back when databases were flat – before they could be considered relational in any form – developers could use repeating fields to store different values within a single field, simulating a relational structure. For example, in a scheduling app, you could specify “Days” as a repeating field that could store values such as Monday, Wednesday, Thursday, etc., with each day name in a different repetition. These values are searchable as they would be in a typical database field however, you could not find all records where Thursday was entered into the third repetition only. Your find would return all records where Thursday was entered into any repetition. You can also sort your records by a repeating field, but the sort will use the value from the first repetition only and you can’t re-sort the values within the field repetitions. You’ll find many more details on use cases for and opinions about repeating fields on the web.
At this point with all of the new tools and features in the FileMaker Platform, I rarely use repeating fields anymore. That’s not to say that I have any issues with them, but there are just other ways of achieving the functionality that they more or less offer. When I’m teaching FileMaker classes and we start specifying fields, someone almost always asks me what to set repetition to during the in-class exercises. My stock answer is 1! I then explain how repeating fields originated in the product before FileMaker was anything more than a flat file database. Basically, it was some application developer’s solution to simulate a related table without having any relationships. They were a gift initially until they started causing a lot of complications.
Recently I had a client whose database has been in continual development for a couple of decades. He asked me to review a script outline that would allow him to move data from a set of repeating fields into a new child table. At first, I expanded on his script idea as I didn’t have many details as to how or why he wanted to do this. Maybe he only needed the data moved when some other value or condition was met so a script trigger could be used to move the data. There are actually many other scenarios that would justify scripting out this process.
SEPARATING REPEATING FIELDS
This client has a strong programming background and has been working with FileMaker for many years now, so I assumed he knew enough about repeating fields to justify this approach. Then, almost as an afterthought, I suggested that he could just use some built-in tools and export the records to a FileMaker file. Upon importing that data, he would have the option of splitting the repeating fields into records or keeping them in the original record.
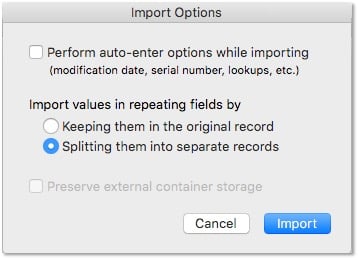
Turns out he was unaware of that feature! Since it also turned out that this would be a one-time operation of moving all the data out of the repeating fields and into a child table, it was far simpler than he had imagined. Sometimes being an old FileMaker developer pays off!
Just to round this out a bit, there could be a number of ways to script this out. My original suggestion to the client was to use repeating variables. Since the nature of repeating fields is that there can be null repetitions between values, he could loop through the repetitions to clean up the data like stranded spaces, returns or whatever and only create $variable[n] for repetitions that had valid data. He could then change the context to the child table and create records for each $variable[n] that was created. This process would be done for each record in the found set.
Even as I write this, many other approaches also come to mind, so I’m not suggesting this is the only approach or even the best approach. But no matter how you design that script, it would be far more development work and far more time-consuming than just exporting your found set and then importing it back in.
Feel free to share your repeating fields tactics.